
I Orchestrated a Fake History Project - and Ended Up Rebuilding Our ML Stack
A tale of Dagster, DuckDB, and accidentally learning infrastructure


You know that feeling when you discover a tool that rewires your entire mental model?
That was me, the first time I saw a Dagster asset graph. It felt less like writing code - and more like mapping a universe.
I didn’t plan to become a data orchestration evangelist. I just wanted to sync some fictional lore from my world-building notes into DuckDB. (Like any totally normal data scientist.)
Dagster was my first orchestration tool. I’d never used Airflow or Prefect. But the moment I saw how assets worked, something in my brain clicked - and it clicked hard.
Within a few weekends, I had built a personal pipeline to ingest lore data from the World Anvil API using dlt and visualize it in DuckDB. A few weeks later, I was building production ML pipelines at work with Dagster, orchestrating everything from Postgres to S3 to a SageMaker feature store, with W&B monitoring, without ever touching a Jupyter notebook in production.
This is the story of how I went from fake timelines to real retraining flows - and why I think Dagster might be the best thing to happen to my MLOps brain.
ETL Without Orchestration: My Pre-Dagster Life
Before Dagster, I’d done plenty of ETL work - just never with an orchestration tool. At IBM, I worked on projects that ranged from helping to build a data lake to speeding up survey data cleaning pipelines. Everything was pure Python, stitched together by hand. It worked, and I genuinely enjoyed it, but it lacked a clear concept of lineage, scheduling, or visibility beyond simply “did the script run?” I’d heard of Airflow, but never used it - I didn’t yet have use cases that required scheduled jobs or multi-step dependencies. At the time, orchestration felt like something for other people’s problems.
Conworld Chaos as a Learning Platform
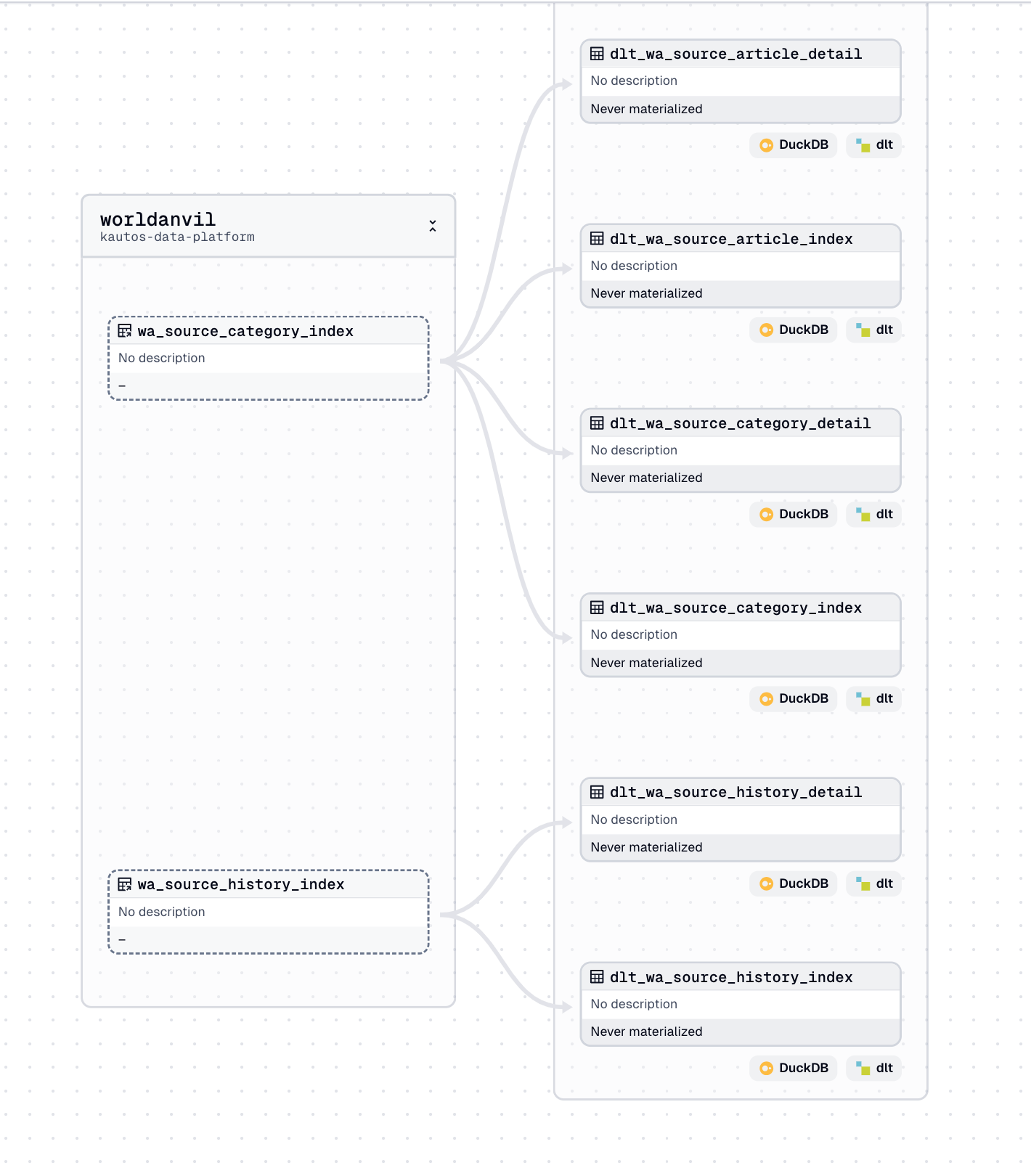
I first heard about Dagster from a data engineer who used it to modernize his company’s data infrastructure. That stuck with me. I was curious, but still didn’t have a clear work use case - so I did what any totally normal person would do: I used it to build a pipeline for my fictional universe.
I had been working on a conworld project and wanted to pull structured lore data from World Anvil’s API - think gods, events, geography, prophecies - and store it in DuckDB. I used dlt for ingestion and brought in Dagster to orchestrate the flow. What started as a side project quickly turned into an experiment in asset-based thinking, data lineage, and cleanly defined dependencies.
To my surprise, Dagster didn’t feel like “yet another layer.” It felt like a clarifying lens - one that let me see how every part of my pipeline fit together. And once I saw how easy it was to map dependencies and materialize assets, I couldn’t unsee it.
Rebuilding My Work Pipelines - This Time With Dagster
When the time came to build ETL pipelines at work, it was a greenfield opportunity - nothing had been orchestrated yet. Thanks to my personal project, I already had the muscle memory for Dagster. So when I needed to move data from our PostgreSQL database to S3, transform it for a SageMaker feature store, and trigger ML retraining with Weights & Biases logging, I reached for the tool that had already earned my trust.
This wasn’t just a toy pipeline - it’s becoming the backbone of our MLOps stack. Dagster handled the orchestration, dlt handled ingestion, and I avoided SageMaker Pipelines entirely because I refuse to run notebooks in production like it’s 2016. The result was a clean, declarative flow that made our data and model updates easy to monitor, reason about, and maintain.
And the best part? It didn’t feel like starting from scratch. Thanks to the absurd decision to structure a fictional theology database, I already knew what I was doing.
Why Dagster Stuck: A Few Reasons
Plenty of tools are powerful. Dagster is powerful and intuitive. Once I started using it, a few things stood out:
Asset-based thinking just makes sense. Instead of writing imperative scripts and chaining them together manually, I could define what and let Dagster handle the when. It’s a mental model that scales.
The visual graph is genuinely helpful. I’m used to tools claiming “observability” but giving me a glorified log dump. Dagster’s asset lineage view made it easy to see the full pipeline at a glance and spot issues before they became problems.
Local dev actually feels good. Spinning up
dagster devand running isolated asset tests gave me the confidence to move fast without wrecking production. It made experimentation safe and productive - both for me and my team.It plays nicely with real tools. Whether it was dlthub for ingestion, DuckDB for local storage, or SageMaker + W&B for model retraining and monitoring, Dagster didn’t get in the way. It orchestrated. Cleanly.
I wasn’t just building workflows - I was thinking in data assets, lineage, and clean dependencies. And that shift stuck with me.
From Fake Gods to Real Models
What started as a lore-syncing side project turned out to be the perfect training ground for production MLOps. Dagster helped me wrangle timelines of fictional prophets, then helped me structure pipelines for real-world machine learning. The tooling didn’t change - just the stakes.
That’s the thing about side projects: you never know which ones will accidentally teach you everything you need. For me, building pipelines for a fantasy world gave me the confidence, intuition, and practical skills to architect real ones from scratch.
Whether it’s syncing fake deities or retraining a model that drives real decisions, it turns out the same principles apply: build cleanly, define your assets, and keep your lineage clear.

If you've ever built something absurd that quietly taught you real-world skills - I’d love to hear about it. Bonus points if it involves cats, fictional timelines, or a petty refusal to use Jupyter notebooks in prod.